There’s a saying in health information technology that applies to the struggle to eliminate duplicate patients and medical records: Garbage in, garbage out.
It’s a simple way of expressing the fact that inaccurate data leads to inaccurate results, no matter how sophisticated the program.
Of course, eliminating bad data in the form of duplicate patients and medical record overlays is the goal of patient matching, but, until recently, those efforts have been handicapped by the quality of the records themselves.
Let me explain. Matching patients is done by master patient index (MPI) technologies. These are standard with most EHRs, and they automatically link patient data in the system and flag duplicate records. Enterprise MPIs (EMPI) from third-party vendors, like 4medica, go beyond single EHRs to link patient data across multiple systems, such as other EHRs, labs, etc.
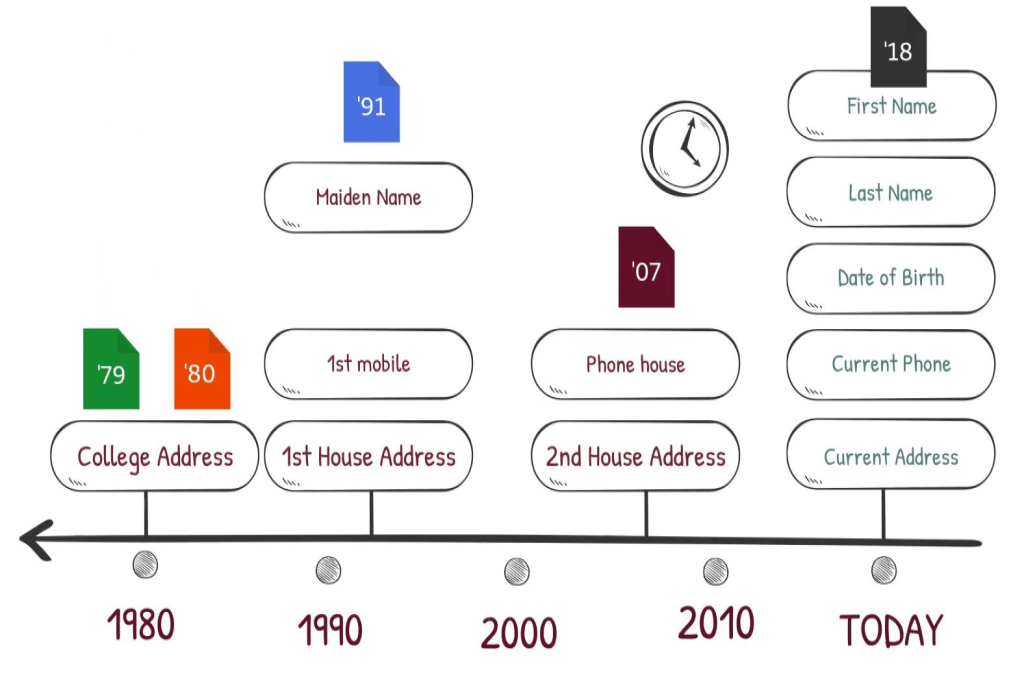
MPIs and EMPIs depend on algorithms to compare demographic data, like names, phone numbers, mailing addresses, and birthdates, from two patient records to see if they belong to the same patient. The higher the volume of matching data, the more likely the algorithm will decide the records match.
These processes use two types of algorithms. The simpler, known as deterministic, looks for identical matches between each data element to decide if records match. Probabilistic algorithms are more sophisticated. They take into account numerous other factors, such as statistics and data weighting, to determine the probability that records match. As a rule, these are more accurate at resolving minor discrepancies to determine a match.
However, both types of algorithms depend on the accuracy and comprehensiveness of the data in the patients’ demographic attributes. If the attributes are widely divergent or incomplete, the algorithms can’t determine a match. That’s the “garbage in, garbage out” problem.
But there is a new approach to patient matching that overcomes this obstacle.
Referential matching compares the demographics of patients against highly sophisticated databases that go back decades, which are routinely updated and include virtually every citizen in the country. This ocean of data allows for far greater accuracy in patient matching.
But 4medica doesn’t stop there. We take referential matching to the next level by incorporating machine learning, an important component of the growing field of data science. Machine learning is a subfield of artificial intelligence that gives computers the ability to learn without explicitly being programmed. This allows for faster searching and matching and can eliminate duplicate patients in milliseconds.
So, by not relying on “garbage” data, 4medica’s process ensures that patient matching is fast and accurate.
