Jane Doe has an extensive medical record, full of appointments, diagnoses, treatments, prescriptions and lab results. Her healthcare providers use the record to track her health and determine the care she needs.
Jayne Doe also has a medical record that is relied upon by her healthcare providers.
What those providers don’t know is that Jane Doe and Jayne Doe are the same person and their medical records are duplicates, each containing part of her complete history, but omitting other data. The duplicate records were created by accident due to a data entry error or discrepancies among the patient registration forms.

As a result, Jane/Jayne Doe could be in danger of a misdiagnosis or mistreatment based on her duplicate or incomplete records.
Machine learning is doing great things in medicine, including improving medical diagnosis and drug manufacturing. It’s also improving healthcare in another way that doesn’t earn headlines but is at the core of care delivery: eliminating duplicate patient records, like the ones described above, and providing high-quality data for patients and providers.
Duplication of patient records is one of the most serious problems with healthcare data quality – and it’s more common than many people think. Duplication rates have been found to be as high as 30% in some healthcare organizations and a 10% rate is common.
Typically, this is caused when someone makes a mistake when registering a patient or entering data, such as transposing digits in a Social Security or phone number. Registration forms vary by organization, with some requiring more identifying detail than others. Patients move addresses and change phone numbers as well, with each iteration creating the opportunity for a duplicate record.
Duplicates and other patient-matching errors don’t only pose a medical risk; they cause costly inefficiencies and dilute the value of a healthcare organization’s data. Duplicate patient records cost healthcare organizations nearly $2,000 per inpatient stay and $800 per emergency department visit. In addition, a third of claims denials can be traced to inaccurate patient identification or health data.
Once detected, duplicate records typically must be corrected by hand, a long and tedious process that requires healthcare employees to pore over files and billings to make sure the right data is attached to the right patient and duplicates are eliminated.
However, a growing number of hospitals, health systems, laboratories and practices are turning to machine learning to eliminate duplicates and overlays, which are more dangerous and caused when patients’ records are mixed together.
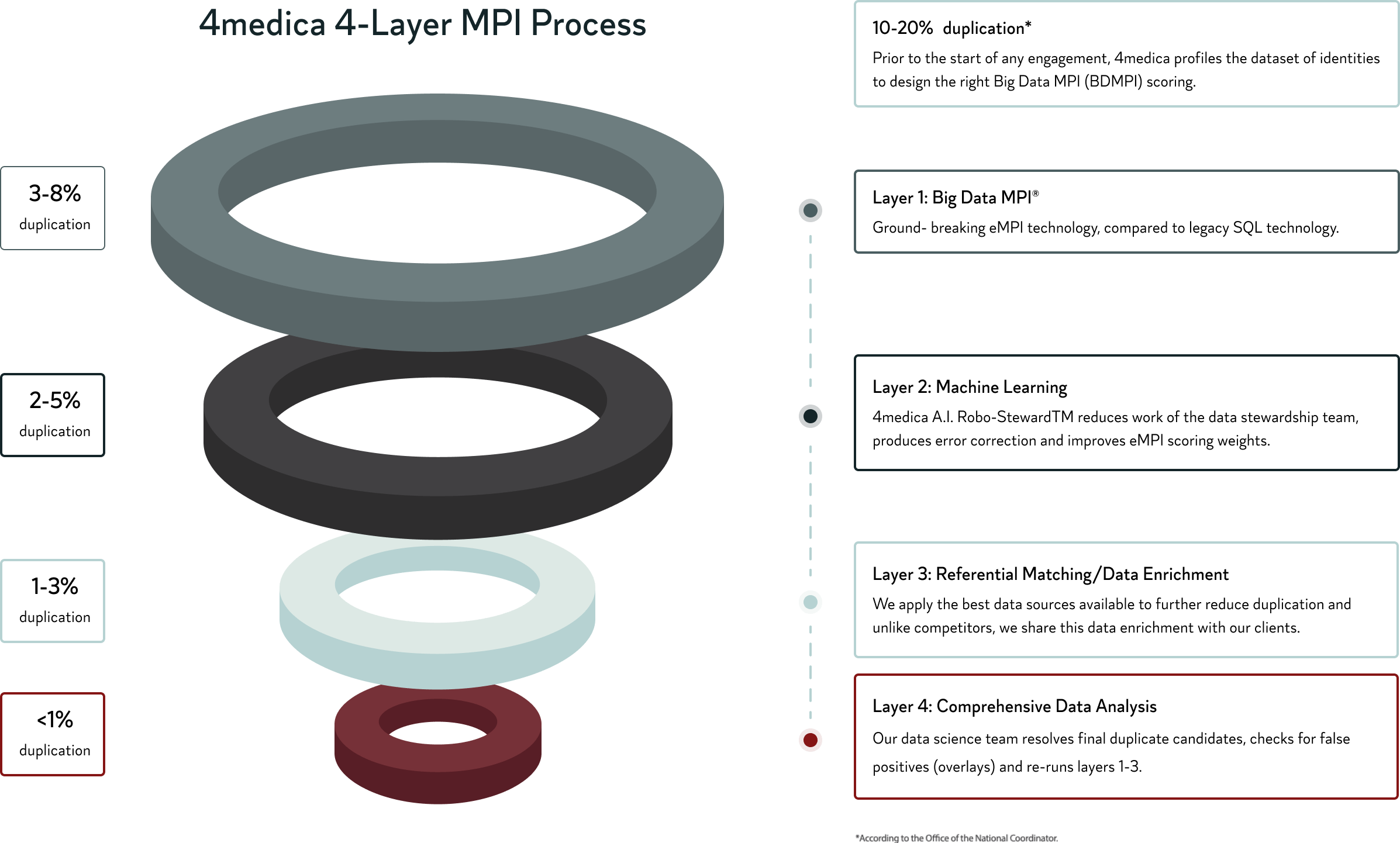
A typical four-layer process runs an organization’s data through an ML-powered identity resolution engine to reduce duplication rates to as low as 1%. It’s not only faster and more accurate, it frees up staff to perform more important work.
Machine learning not only clears up duplicate records, it also prevents their creation by analyzing all fields in a medical record database and matching the results and signifiers to the correct patient before the record is finalized.
This article was initially published by insideBIGDATA. Click here to view article
