Achieving Heath Data Quality through technology
The Idaho Health Data Exchange incorporates advanced data sharing capabilities and actionable data insights. Learn how 4medica used technology to help them reduce duplication rates below 1% and deliver a longitudinal health record that stakeholders could trust to achieve optimal care management.
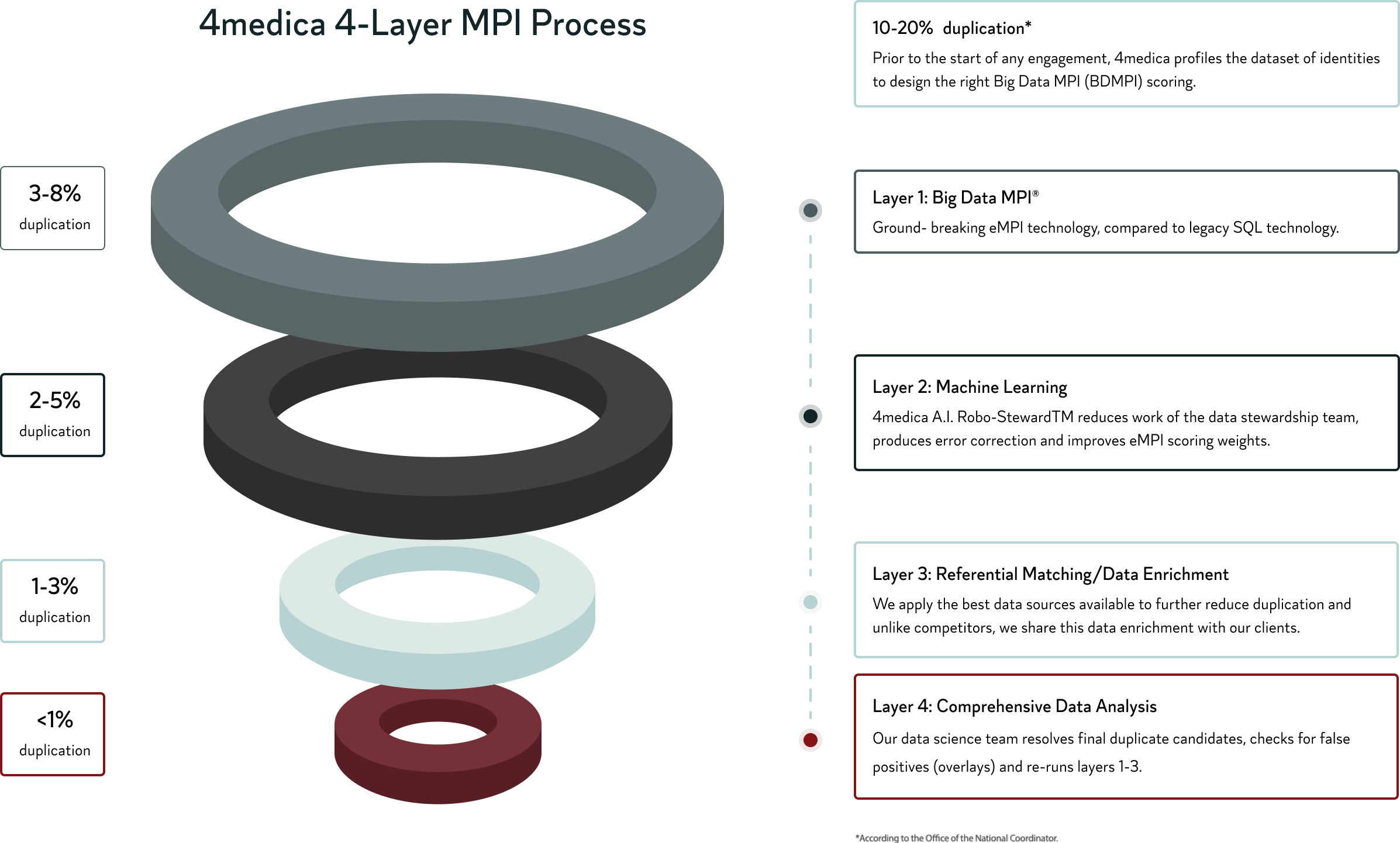
By utilizing the industry’s most technologically advanced MPI process, 4medica has revolutionized how HIEs & HINs can analyze and implement big data. Our 4-layer approach simplifies implementation and guarantees dramatic success of <1% patient duplication.
Good quality data is the foundation for accurate healthcare reporting and statistical analysis; it creates an atmosphere of trust where healthcare data is usable and provides value to participants and ultimately patients. It also allows for an effective revenue cycle management strategy, which can help reduce burnout.
